-
Objects as Points (CenterNet) 논문 리뷰CV & ML 2019. 12. 22. 14:34
석사 1학기 차 새로운 프로젝트에 참여하게 되었다.
산업 현장에서 블랙박스처럼 카메라를 달아서 물체를 탐지하는 기술 개발이었다.
저사양 임베디드 보드에서 가볍고 빠른 object detector를 연구하다 선배가 발견하신 CenterNet을 보고 논문을 읽어보고, 직접 학습시키고 개발해보았다.
먼저, 논문 리뷰를 먼저 해보겠다.
참조 링크:
CenterNet 논문: https://arxiv.org/pdf/1904.07850.pdf
논문 리뷰 참조:
https://nuggy875.tistory.com/34
[Object Detection] CenterNet (Objects as Points) 논문 리뷰
지금까지 Real-Time Task를 요구하는 Object Detection 문제를 해결할 때는 주로 YOLO(You Look Only Once)를 사용하였습니다. 최근 빠른 성능(FPS)을 가지는 Detector를 요구하는 프로젝트를 진행하게 되어 YOLO..
nuggy875.tistory.com
저자: Xingyi Zhou, Dequan Wang, Philipp Krähenbu?hl
Abstract
현재 유명한 object detector들은 이미지에서 axis-aligned box(shape이 결정된? 박스?) 찾아서 물체를 탐지한다. 물체가 있을 법한 위치랑 그 박스 안의 물체를 분류하기 위해 시간이 많이 든다.
그래서! 이 논문은 물체를 포인트로 인식하는 방법을 제안한다. 포인트라는 건 bounding box의 중심점이다.
특징
1. end-to-end differentiable : input으로 image 하나가 들어가면 output도 하나! gradient 계산 시 편리하다.
2. Simpler, faster, and more accurate!
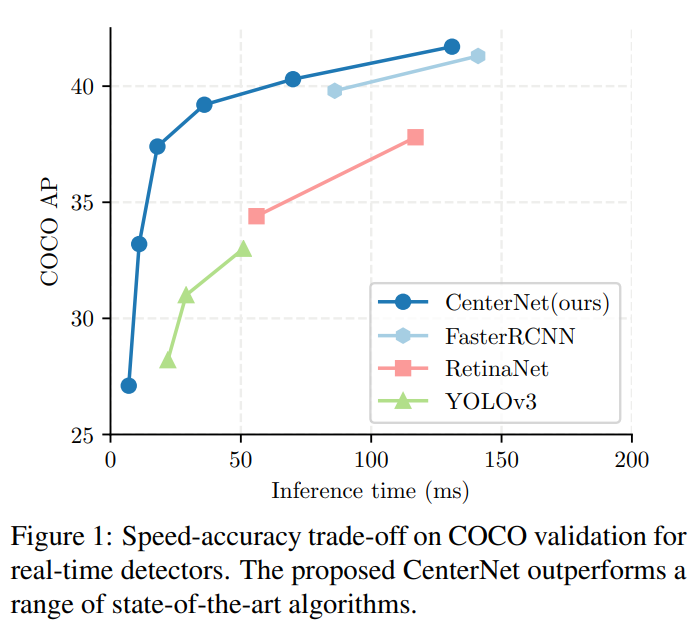
Introduction
end-to-end 미분이 가능한 one-stage detector은 two-stage detector보다 빨라서 real-time detector로 활용된다. one-stage detector와 관련이 깊은 논문은 YOLO, SSD, Focal Loss 등이 있다. 이 detector들은 anchor( 물체가 있을 법한 위치의 region)들을 이미지에 복잡하게 위치시켜서 물체들을 분류한다.
그런데, CenterNet은 물체를 포인트로 나타내서 나머지 정보들(크기, 차원, 3D 범위, 중심방향 자세)은 중심 위치에서 regression하는 방법이다. 즉 keypoint estimation 방법을 사용한다. (관련 논문: OpenPose, Associative embedding, Starmap). 이 모델의 output 중 하나인 heatmap에서 peak 부분이 center point에 해당한다. 모델 학습은 dense supervised learning (Associatiative embedding, Starmap) 방법을 이용한다. 모엘 테스트 때는 forward-pass 만 하고, (post-processing 방법 중 하나인) non-maximal suppresion 과정은 따로 없다.
CenterNet의 또 다른 장점은 3D object detection과 multi-person human pose estimation까지 쉽게 활용될 수 있다.
각각의 task에 따라 model의 output이 다르다.
Object detection: keypoint heatmap, local offset, object size
3D object detection: 3D size, depth, orientation(방향)
Pose estimation: joint location, joint heatmap, joint offset
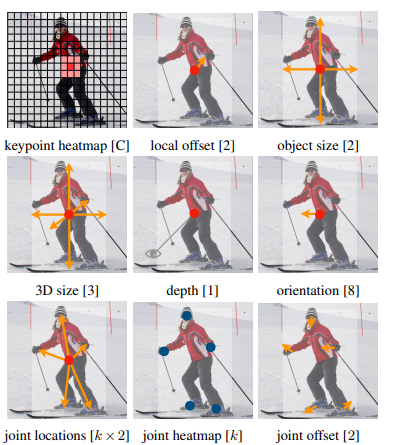
outputs of CenterNet for different tasks (위: object detection, 중간: 3D object detection, 아래: pose estimation) Related work
Object detection by region classification
RCNN, Fast-RCNN은 둘 다 물체가 있을 법한 위치들을 엄청 많이 선정하고 각각의 위치에서 물체를 분류한다. 아주 유명한 object detector이지만 너무 느리고 low-level의 region proposal 방법입니다.
머신러닝의 object detection에서 자주 나오는 용어를 알고 싶은 분들은 아래 사이트를 추천드립니다! 잘 설명되어 있어서 저도 많은 도움을 받았던 글입니다.
“Tutorials of Object Detection using Deep Learning [1] What is object detection?”
Deep Learning을 이용한 Object detection Tutorial - [1] What is object detection?
hoya012.github.io
Object detection with implicit anchors
Faster FCNN은 네트워크 안에서 region proposal이 실행됩니다. ~
CenterNet은 기존의 one-stage detector들 (YOLO, RetinaNet, SSD)와 비슷합니다. 이들은 중심점이 single shape-agnostic anchor를 사용하는 것처럼 보이죠. (너무 해석이 애매...) 그렇지만 3가지 면에서 CenterNet은 차이점을 보여준다. (개인적으로 명확하게 다른 점인지 해석하는 데 좀 어려웠습니다. 아마 제가 YOLO, RetinaNet, SSD를 아직 잘 몰라서 그런 것 같아서 나중에 이 detector들도 논문을 읽어봐야 겠습니다.)
1. Assign the "anchor" based solely on location, not box overlap
box를 선정하고 물체 분류가 아니라, 물체의 center point가 있을 법한 위치를 선정한다는 말 같습니다. (마치 multi-person pose estimation 문제에서 top-bottom / bottom-top 방법의 차이처럼..)
2. Only one positive "anchor" per object -> No need for NMS
하나의 물체에는 하나의 positive "anchor"만 있기 때문에, Non-Maximum Suppression필요 없음
3. 다른 detector들 보다 output 해상도가 커서 여러개의 anchor가 필요 없다.

기존 anchor based detection 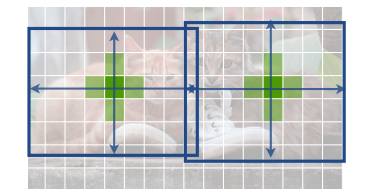
CenterNet 방법: center point based detection Object detection by keypoint estimation
CornerNet과 extremeNet은 centerNet 보다 먼저 keypoint estimation 방법을 object detection으로 활용한 논문입니다. CornerNet은 bounding box의 2개 코너를, ExtremeNet은 모든 물체의 top-, left-, bottom-, right-most, center points를 탐지했습니다. 하지만 이 논문들에서는 combinatorial grouping stage (한 물체당 1개 이상의 점들이 있기 때문에 서로 연관되는 점들은 한 그룹에 넣는 과정이라는 ...?) 때문에 모델의 속도가 느려지게 되었습니다.
그러나 CenterNet은 하나의 점만 사용하기 때문에 grouping 과정이 필요 없습니다.
Monocular 3D object detection
3D box는 자율 주행 기술을 개발하면서 필요성이 두각되었습니다. 관련 논문: Are we ready for autonomous drivign, Deep3Dbox, 3D RCNN, Deep Manta 등이 있는데, CenterNet은 Deep3Dbox나 3DRCNN 방법과 유사합니다. 그렇지만, CenterNet이 더 단순하고 빠릅니다.
Preliminary
수식 I, R, C, W, H 설명
I: Input 이미지
W: Input 이미지의 width
H: Input 이미지의 height
R: output stride
C: keypoint 종류 갯수 - (예) human pose estimation 경우 사람 관절 17개이므로 C = 17
CenterNet은 keypoint(=center point) heatmap 값을 예측하기 위해 fully-connected encoder-decoder 네트워크를 4개 사용해서 결과를 보였다. keypoint predicition network는 CornerNet것을 사용했다.
(수식)
'CV & ML' 카테고리의 다른 글
[논문] Deep 3d human pose estimation: A review (0) 2021.11.22 MCU 보드 기반 도서관 서가 안내 로봇 제작 (0) 2021.11.04 RGB-IR 카메라 통합 3D point cloud 구현 (0) 2021.11.03 초광각 렌즈의 왜곡 보정과 특징 융합형 인식 모델 연구 (0) 2021.11.03 [YOLO] 소량의 데이터셋 경로를 포함하는 text 파일 생성 (0) 2020.05.06